Abstraction and Encapsulation
Introduction

Both abstraction and encapsulation refer to the idea that modules should have clear boundaries and should not expose their internal workings to the outside world. This is a fundamental principle of software design that allows us to focus on one piece at a time and make changes without needing to understand other modules. This is a powerful tool that allows us to build complex systems that are still easy to understand and work with.
We're combining these two concepts because they are the same core idea, just viewed from opposite sides. The core idea is that modules should have an inside and an outside that is enforced through some mechanism. Components on the inside should have visibility and access to the inner workings of the module, while anything on the outside should have not need or care to know how the module is implemented or functions.
Why Abstraction and Encapsulation Matter
Having clear boundaries makes for looser coupling between modules. If some component on the outside knows, and relies on, the inner workings of another module, then that component is tightly coupled. Each module can no longer be modified in isolation.
Having clear boundaries also plays a significant role in reducing cognitive load. If I don't need to rely on the implementation details of another class, then I don't need to try to hold those details in my mind while I work.
Big Ball of Mud Systems
Consider what happens when a system doesn't use any abstractions at all. The inner workings of each module are available and can be relied on by any other components.
If the project is small then this might not be a big deal. We can mentally track all of the details that we need to do our work. And because it is small, there aren't many other engineers whose work I need to keep track of.
As the codebase grows and more developers add their contributions, it becomes harder and harder to keep track of. Eventually the system becomes too complex for us to track completely. We can no longer understand how our changes will impact the system as a whole. Such systems are fragile and difficult to maintain or extend.
These types of systems are often referred to as Big Balls of Mud. They are so entangled and convoluted that developers are scared to even fix known bugs because they might break something else. This sort of problem isn't uncommon and most large companies end up creating a system like this at some point.
I was listening to talk by Randy Shoup, the former Chief Architect at eBay, where he said that the first implementation of the platform reach 2.5 million lines of C++ code before it was finally replaced. Even worse, every one of the lines was in a single file. They were stripping out the few abstractions they had because the compiler enforced a limit of 65k functions per file.
Imagine for a moment how hard it must have been to work in that environment.
Avoiding the Mud Pit
Creating good abstractions that allow us to focus on one piece at a time are what allow us to avoid building a big ball of mud. They allow us to modify, extend, or even replace a single module without needing to significantly change any others.
This still requires discipline from the developers. Avoid the temptation to peak through an interface when writing your code. There is nothing wrong with knowing the details, but you should never rely on them when building something new.
When building interfaces for your modules, be sure to clearly communicate what they are for and how they should be used. Your descriptions shouldn't share implementation details, but should give enough information for someone to use the module effectively.

General Principles
Abstractions are Everywhere
Abstractions exist everywhere in software engineering and we rely on them constantly.
- Programming languages are just abstractions for machine instructions.
- The operating system hides hardware details.
- Libraries give us flexible tools where we don't need to know their inner details to use them.
- Threads and parallelism are hiding the complex details of their implementation so we can focus on the important things.
Despite relying on abstractions constantly most developers have a tendency to ignore them in their own work.
I've had developers that I respect argue that adding abstraction layers when they aren't strictly required is a form of over-engineering, but I disagree. Adding a clearly defined interface to a module is a form of documentation. Even if it isn't strictly required, it tells other developers how the module should be used and what they can expect from it. It also shows future developers where the boundaries of the module are and what they can rely on.
Abstraction Provides Flexibility
"As soon as one freezes a design, it becomes obsolete."
-- Fred Brooks: Mythical Man Month
Legacy code is often described as code that we are afraid to change. A lack of clear boundaries around modules is a major reason for this. If we can't change a module without breaking something else, then we are stuck with the code as it is.
No matter how clear our abstractions, changes to the interface will always be complex. We hope that our modules are flexible enough to allow us to make changes without needing to change other modules, but this is never guaranteed. When we do need to change the interface, we need to be careful to ensure that we don't break anything else.
By preference the consumer of the module should be the one to drive the changes. They are requesting new functionality or a change in behavior. Start with the interface and work backwards to the implementation.
All Abstractions Leak
"All non-trivial abstractions are leaky"
-- Joel Spolsky
Building abstractions becomes even more complicated when you realize that they all leak. That is to say, they all expose details about the inner workings of the system that they are supposed to protect.

For example, if I want to build an extremely fast system, something that is running at the limits of what the hardware can provide, then many details that I could normally ignore can become serious concerns. Things like garbage collection and random access memory are potential problems.
Normally these abstractions are great. They simplify our programming considerably, but if I want to maximize performance, then I need to concern myself with their inner details. Their presence makes latency variable.
Garbage collection introduces arbitrary delays at unpredictable intervals. Because processors are orders of magnitude faster than RAM, I need to start paying attention to things that I usually ignore. I need to know about caching and pre-fetching in order to maximize performance.
Abstractions just aren't as helpful when I need to know those inner details.
Abstractions and Testing
Abstractions go hand in hand with testing. If I have a clear boundary between modules, then I can test them in isolation. I can write tests that verify that the module behaves as expected without needing to know how it is implemented.
Automated tests that verify the abstraction and not the implementation give us the freedom to change the implementation without needing to change the tests. This is a powerful tool that allows us to refactor our code with confidence.
When the tests validate the implementation, then they become a barrier to change. If I change the implementation, then I need to change the tests. This is a problem because it means that I can't refactor the code without breaking the tests.
For classes that rely on the abstraction, I can use mocks or stubs to simulate the behavior of the module. This allows me to test that my class works as expected for all possible behaviors of its dependencies.
Picking the Right Abstraction
Deciding on the right abstraction is a difficult task, and is often more art than science. Any solution needs to be tailored to the specific problem at hand. There are some general principles that can help guide the decision.
Accuracy Doesn't Matter
"All models are wrong, but some are useful."
-- George Box
Choosing abstractions is really about modeling. We expose a model of the system that is simpler than the system itself. The goal is to make the model useful, not accurate. The model should be useful for the task at hand, but it doesn't need to be accurate in all cases.
No matter how good our model is, it will never be the real thing, and it shouldn't be. The whole point is simplification. We want to make the system easier to understand and work with. Which means creating a simpler model that only exposes the details that are important for the task at hand.
Real World Example: Maps
A fun real world example of this is maps. Maps are a model of the world that is intended to be useful, but not necessarily accurate.
Consider the Mercator projection, which is designed for navigation. It distorts the size of land masses, but it preserves angles. If you plot a course on a Mercator map, then you can follow that course on the real world and you will arrive at the correct destination. It won't be the shortest path, but it will be a correct path. This map is inaccurate in many ways, but it is useful.
A totally different type of abstraction is used for train and subway maps. This map is for the TriMet Light Rail system in Portland, Oregon.
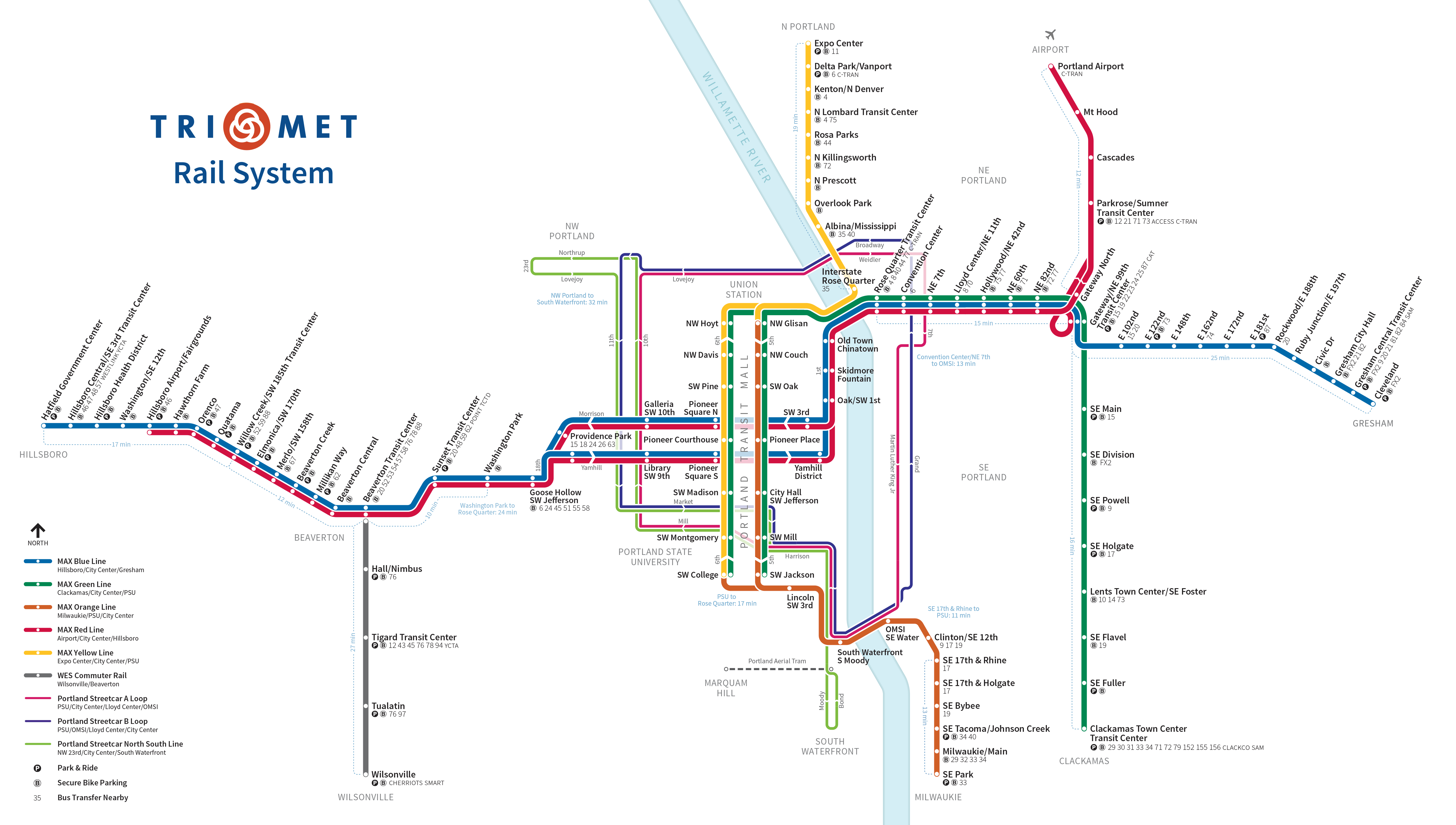
It is a highly abstracted map that shows the stations and the lines that connect them. It doesn't show the actual distances between stations or the exact path that the trains take. It would be useless for anyone trying to navigate the city on foot, but it is perfect for someone trying to navigate the rail system.
This approach was invented by Harry Beck in 1931 for the London Underground. It has since been adopted by many other transit systems around the world. The accuracy of these maps is not important. What is important is that they are useful for the task at hand. The same is true for software abstractions.
Domain Based Abstractions
In many cases the problem domain will suggest the right abstraction. If we are working on a system that models a bank, then we will have abstractions for accounts, transactions, and customers. These abstractions are natural and make sense in the context of the problem.
Spend time understanding how the problem domain is broken down and use that to guide your abstractions. This will make the system easier to understand and work with for . It has the added benefit of making the system easier to explain to non-technical stakeholders. If they understand the problem domain, then they will understand the system.
This approach takes time and effort, but tends to work extremely well. If you are new to the problem domain, then plan to spend time talking to senior engineers and domain experts. They will be able to help you understand the problem and suggest useful abstractions. This is a critical part of the onboarding process for new engineers.
Hiding Accidental Complexity
Adding abstractions to isolate the accidental complexity of a system is almost always the right idea. We want to hide details like:
- Connection failures
- Failing a database query
- Handling network timeouts
- Race conditions
- etc.
The business logic of our system shouldn't need to worry about these details. They are accidental complexity that we can hide behind an abstraction. This makes the business logic easier to understand and work with.
Isolate Third Party Systems
Relying directly on third party systems is generally a bad idea. They are outside of our control and can change at any time. If we rely on them directly, then we are at the mercy of their changes. I try to add an abstraction layer between my system and anything that is outside of my control. Things like databases, external APIs, and libraries should all have an abstraction layer that I can use to limit the impact of changes.
This doesn't apply for features provided by the programming language or the operating system. These are stable and unlikely to change. It is the third party systems that we need to worry about.
Third party, in this context, doesn't just mean external services from outside the company. It also includes any system that is outside of our control. This could be a different team in the same company, or a different part of the system that is maintained by a different team.

Prefer Information Hiding
It is generally better to prefer a more general representation over a more specific one. General purpose modules tend to be more useful and flexible than specific ones. Consider the following three function signatures:
fun mapToList(map: HashMap<String, Int>): ArrayList<Int>
fun mapToList(map: Map<String, Int>): List<Int>
fun mapToList(map: Any): Any
In this case the second function is the clear winner. It is more general than the first, but still provides useful information about how the module should be used. The third function is too general. It doesn't provide any information about how the module should be used.
While this example is trivial, the principle holds for more complex systems. The more general the interface, the more flexible the module will be. This is a trade-off, however. The more general the interface, the less information it provides about how the module should be used.
Multiple Abstractions
Having multiple abstractions for the same system is a powerful tool. It allows us to focus on different aspects of the system at different times. Users of the module can choose the abstraction that is most useful for their task. This helps to keep the module flexible and useful in a wider range of situations.
When to Avoid Abstractions
There is one main case where abstractions should be avoided. In high performance systems, where every cycle counts, abstractions can be a problem. They introduce overhead that can be unacceptable. Information hiding has a speed impact. It takes time to look up the details of the implementation. This is usually a tiny amount of time, but in high performance systems it can be too much.
This is a case where abstractions should be removed. It shouldn't prevent you from adding abstractions in the first place. Don't remove them until you have identified a bottleneck and can prove that the abstraction is the cause.
Conclusion
Abstractions are critical for creating clear boundaries around our modules. They allow us to focus on one piece at a time and make changes without needing to change other modules. This is a powerful tool that allows us to build complex systems that are still easy to understand and work with.
Getting abstractions right is a difficult task that requires time and effort, but the payoff is worth it. The right abstractions will prevent your system from spiraling out of control and becoming a big ball of mud.
{kind=link}